
在实时交互的客户服务场景中,系统稳定性直接影响企业服务质量和品牌声誉。云呼叫中心作为客户沟通的核心枢纽,其可靠运行对业务连续性至关重要。理解平台稳定性保障机制和故障应对策略,是企业技术选型和风险管理的关键考量。
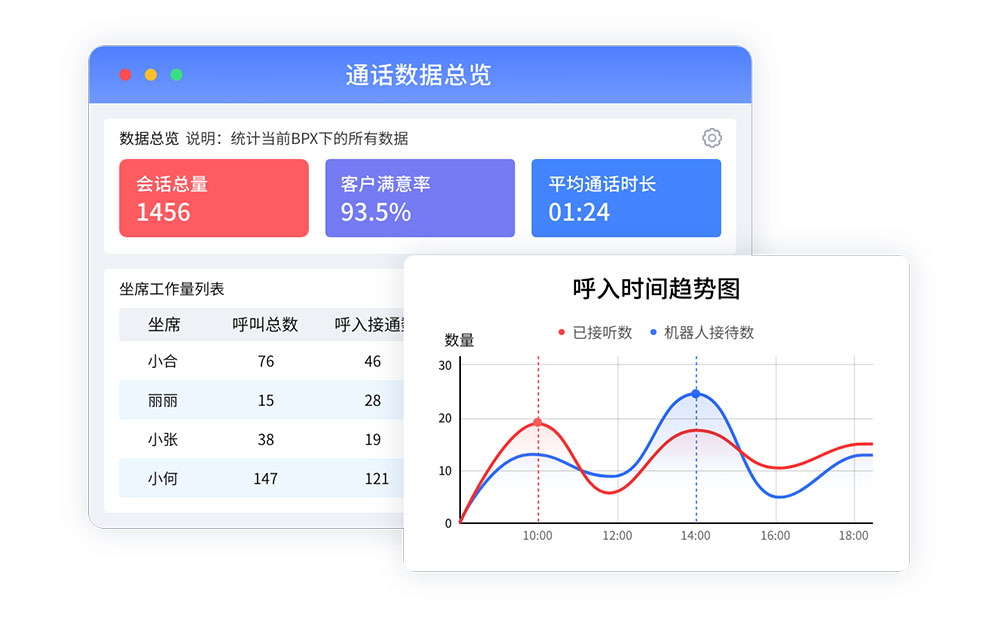
一、基础设施的可靠性设计
1.1 多可用区分布式部署
领先的云呼叫中心采用跨地域的多可用区架构,将服务组件分散部署在相互隔离的物理设施中。单一数据中心故障时,流量可自动切换至健康节点,确保服务不中断。
1.2 负载均衡与弹性伸缩
智能流量分发系统实时监测各节点负载情况,动态调整资源分配。在突发流量高峰时自动扩容计算资源,避免过载导致的性能下降。
1.3 网络链路的冗余配置
与多家运营商建立BGP多线接入,配合SD-WAN技术优化网络路径选择。当主用线路出现延迟或丢包时,可毫秒级切换至备用链路。
二、实时监控与预警体系
2.1 全栈监控的数据采集
从硬件资源、网络性能到应用接口、业务流程,构建覆盖基础设施、平台、应用三层的监控指标体系。每秒数万次的数据采集为异常检测提供坚实基础。
2.2 智能阈值的动态调整
基于机器学习算法分析历史数据规律,自动生成适应业务周期的动态告警阈值。避免固定阈值导致的误报或漏报,提高预警准确率。
2.3 多通道的告警通知
将不同严重等级的告警信息通过短信、邮件、即时通讯工具等多渠道推送至运维团队。关键告警支持自动升级机制,确保问题及时响应。
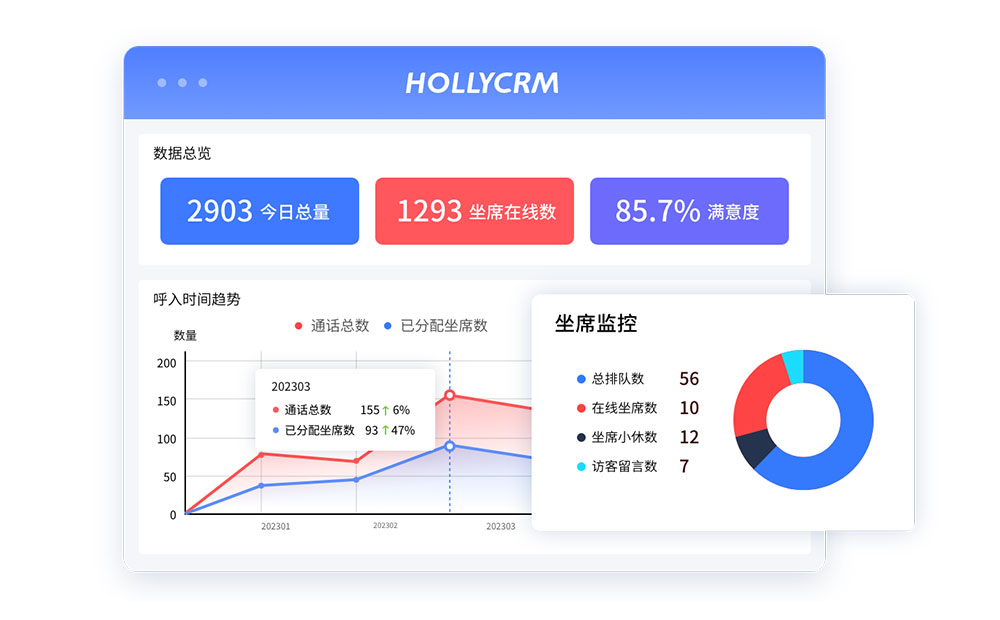
三、数据安全与持久化
3.1 实时同步的多副本存储
采用分布式数据库架构,所有通话记录、工单数据实时同步至多个物理隔离的存储节点。单点故障不会导致数据丢失,满足金融级可靠性要求。
3.2 增量备份的版本管理
除全量备份外,实施分钟级的增量备份策略,保留多个时间点的数据快照。在逻辑错误或数据损坏时,可快速回滚至健康状态。
3.3 端到端的加密传输
从终端设备到云端服务,全程采用TLS加密通道。语音媒体流使用SRTP协议保护,防止通信内容被窃听或篡改。
四、故障应急响应机制
4.1 故障等级的标准化定义
根据影响范围和持续时间,将故障划分为不同严重等级。每个等级对应明确的应急流程、响应时限和升级路径,避免混乱中的决策延迟。
4.2 服务降级的预案准备
在系统部分功能不可用时,预设的服务降级方案可保障核心通话功能优先恢复。如暂时关闭语音分析功能,确保基础呼入呼出不受影响。
4.3 应急通道的快速启用
当主控台无法访问时,备用管理入口和移动端控制面板可立即启用。运维人员通过简化界面执行关键操作,维持基本服务能力。
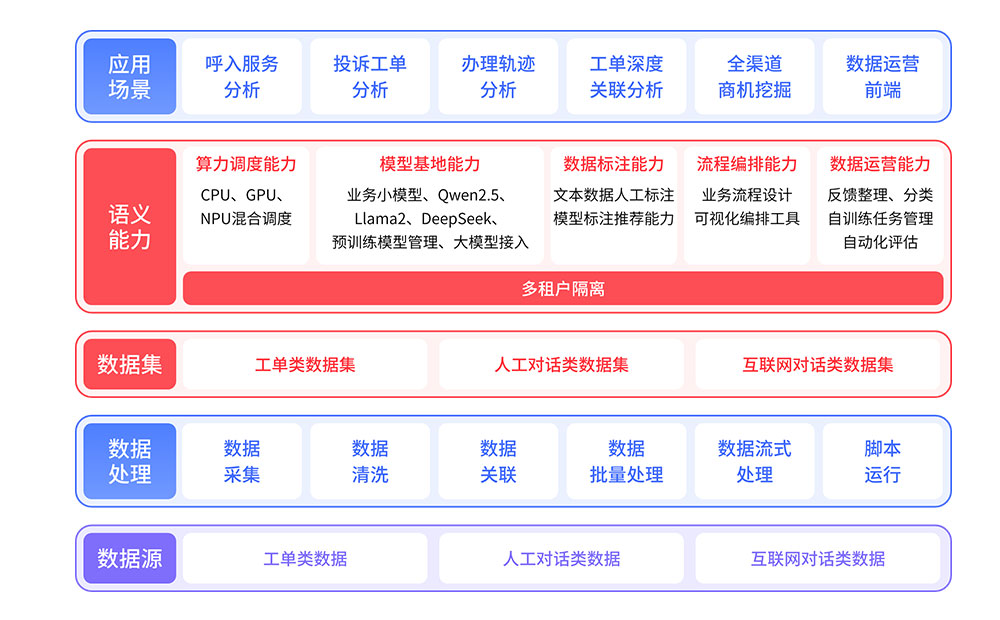
五、业务连续性管理
5.1 容灾演练的定期实施
每季度进行模拟故障切换演练,验证备份系统可用性和团队应急能力。演练结果用于持续优化应急预案和技术架构。
5.2 第三方服务的依赖管理
对依赖的短信网关、支付接口等第三方服务,建立熔断机制和替代方案。当外部服务异常时,自动隔离故障源避免级联影响。
5.3 事后复盘的知识沉淀
每次故障处理后进行根因分析和技术复盘,形成改进措施和知识文档。历史故障案例库帮助团队提升问题诊断效率。
结语:稳定性的系统工程
云呼叫中心的稳定性保障不是单一技术措施,而是涵盖架构设计、监控预警、应急响应和持续改进的系统工程。企业应当选择技术实力扎实的服务商,同时建立自身的应急管理能力,形成双重的可靠性保障。在数字化服务日益重要的今天,投资于系统稳定性就是投资于客户信任和品牌价值。





 申请成功!
申请成功!