
当自然灾害或技术故障导致电力中断时,传统本地化部署的呼叫中心往往陷入全面瘫痪,客户服务被迫中断。云呼叫中心凭借其全球分布式架构和智能灾备机制,正在重新定义业务连续性的标准。本文将深入解析云端系统如何实现"永不掉线"的服务承诺,为企业构建抗风险能力更强的客户服务体系。

一、传统呼叫中心的脆弱性
1.1 单点故障风险
本地化部署依赖单一机房和网络链路,一旦遭遇断电、光缆切断或硬件故障,整个系统即刻停摆。重要客户咨询无法接入,服务承诺无法履行,企业商誉面临严峻考验。
1.2 恢复周期漫长
从故障识别到硬件更换、系统重启往往需要数小时甚至更久。历史数据丢失风险高,灾后数据同步困难,服务完全恢复正常可能需要数天时间。
1.3 灾备成本高昂
自建双活中心需要重复投入硬件和专线资源,中小企业难以承担。多数企业选择接受风险而非投资预防,导致危机来临时损失惨重。
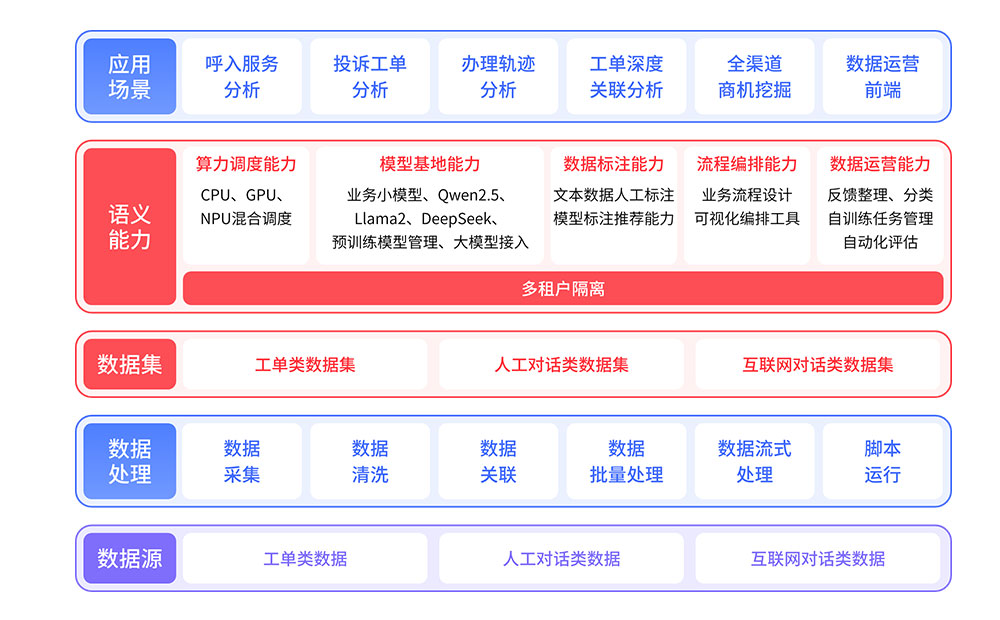
二、云呼叫中心的灾备架构
2.1 分布式基础设施
2.1.1 多可用区部署
云服务商在全球范围建设多个数据中心,服务实例跨区域冗余部署。单一机房故障时,流量自动切换至健康节点,用户无感知。
2.1.2 弹性网络互联
通过软件定义网络(SDN)构建多路径传输矩阵,自动规避网络拥塞和中断点。网络链路故障时毫秒级切换备用路由,保障通话质量稳定。
2.1.3 持久化存储
采用分布式文件系统,数据实时跨区域复制。即使整个可用区不可用,也能从其他区域完整恢复,确保客户交互历史零丢失。
2.2 智能故障转移
2.2.1 健康状态监测
数百个探测点持续检查服务可用性,异常情况30秒内识别。从服务器性能到应用响应,构建全栈监控体系,不留监控盲区。
2.2.2 自动切换机制
预设故障转移策略,无需人工干预即可完成服务迁移。根据故障类型选择最佳恢复路径,优先保障核心通话功能不间断。
2.2.3 渐进式恢复
非关键服务暂缓恢复,集中资源保障基本功能。故障修复后自动同步数据差异,确保系统状态最终一致性。
2.3 业务连续性方案
2.3.1 移动端应急
坐席可通过4G/5G网络接入系统,办公室断电不影响远程服务。智能终端APP保留基础功能,极端情况下仍能维持最低服务水准。
2.3.2 服务降级策略
在资源受限时暂时关闭质检分析等增值功能,优先保障通话接通。动态调整IVR选项,引导客户使用自助服务减轻人工压力。
2.3.3 客户预期管理
自动推送服务异常通知,告知预计恢复时间。排队客户可选择保留位置或接收回调,减少焦虑情绪和流失风险。
三、实施效果的多维价值
3.1 风险抵御能力
实际案例显示,云呼叫中心在区域级灾难中保持99.5%以上的可用性。飓风、洪水等突发事件下,客户服务仍能持续运转。
3.2 成本效益优化
企业以运营支出替代高额灾备建设投入,共享云平台的基础设施冗余。按需使用容灾资源,避免长期维持闲置能力。
3.3 客户信任提升
服务不间断的可靠性转化为品牌美誉度。客户感知到企业的专业性和责任感,长期忠诚度显著增强。
四、部署建议与注意事项
4.1 服务商评估要点
考察云服务商的SLA承诺和历史达标记录,了解其数据中心分布和容灾演练频率。要求提供详细的灾备架构说明和恢复时间目标(RTO)数据。
4.2 混合架构设计
对合规要求严格的业务模块,可采用混合云部署。核心数据本地保存,通话功能使用云端灾备,平衡安全性与可用性。
4.3 定期演练机制
每季度进行灾备切换测试,验证恢复流程的有效性。模拟不同级别的故障场景,持续优化应急预案和人员响应能力。
五、常见误区规避
5.1 过度依赖自动化
保留人工覆盖通道,当自动系统决策失误时可及时干预。关键操作设置二次确认,避免连锁反应导致事故扩大。
5.2 忽视人员准备
技术灾备需配套人员应急预案。建立异地办公预案和紧急联络机制,确保团队在突发情况下能有效协作。
5.3 忽略小规模中断
不仅防范大灾大难,更要应对日常小故障。优化本地网络和电力备份,避免频繁短暂中断影响服务稳定性。
结语
云呼叫中心的灾备优势正在重新定义企业业务连续性的标准。建议企业采取"防御-监测-恢复"的三维策略:先构建弹性基础设施,再完善实时监控体系,最后优化故障恢复流程。值得注意的是,灾备能力不是一次性投入,而是需要持续测试和优化的长期工程。在气候变化加剧、技术风险多元的今天,投资服务连续性就是保护企业核心资产。





 申请成功!
申请成功!